
Apple ha pubblicato uno studio su Manzano, un modello multimodale progettato per combinare comprensione visiva e generazione di immagini senza sacrificare la qualità in nessuna delle due aree.
Lo studio, “MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer”, è stato redatto da un team di circa 30 ricercatori Apple e descrive un approccio unificato che supera alcuni limiti delle architetture multimodali attuali.
I limiti dei modelli multimodali tradizionali
Secondo i ricercatori, i modelli multimodali che supportano la generazione di immagini spesso incontrano un conflitto: la rappresentazione visiva necessaria per comprendere un’immagine non coincide con quella necessaria per generarla.
“Una delle ragioni principali di questo divario è la natura conflittuale della tokenizzazione visiva. La generazione autoregressiva tende a preferire token di immagine discreti, mentre la comprensione beneficia maggiormente di embedding continui. Molti modelli adottano una strategia a doppio tokenizer, utilizzando un encoder semantico per ottenere rappresentazioni continue ricche e un tokenizer quantizzato separato, come VQ-VAE, per la generazione. Tuttavia, questo costringe il modello linguistico a elaborare due tipologie diverse di token di immagine — una proveniente da uno spazio semantico di alto livello e l’altra da uno spazio spaziale di basso livello — creando un conflitto significativo tra i compiti.»
Alcune soluzioni come Mixture-of-Transformers mitigano il problema con percorsi separati, ma risultano inefficienti e poco compatibili con le moderne architetture Mixture-of-Experts. Altre strategie collegano un modello LLM pre-addestrato a un decoder di diffusione, preservando la comprensione ma separando la generazione, con conseguente perdita di benefici reciproci.
Come funziona Manzano
Manzano affronta il problema unificando comprensione e generazione. Il modello usa un LLM autoregressivo per prevedere semanticamente cosa dovrebbe contenere l’immagine e passa queste previsioni a un decoder di diffusione, che genera i pixel finali.
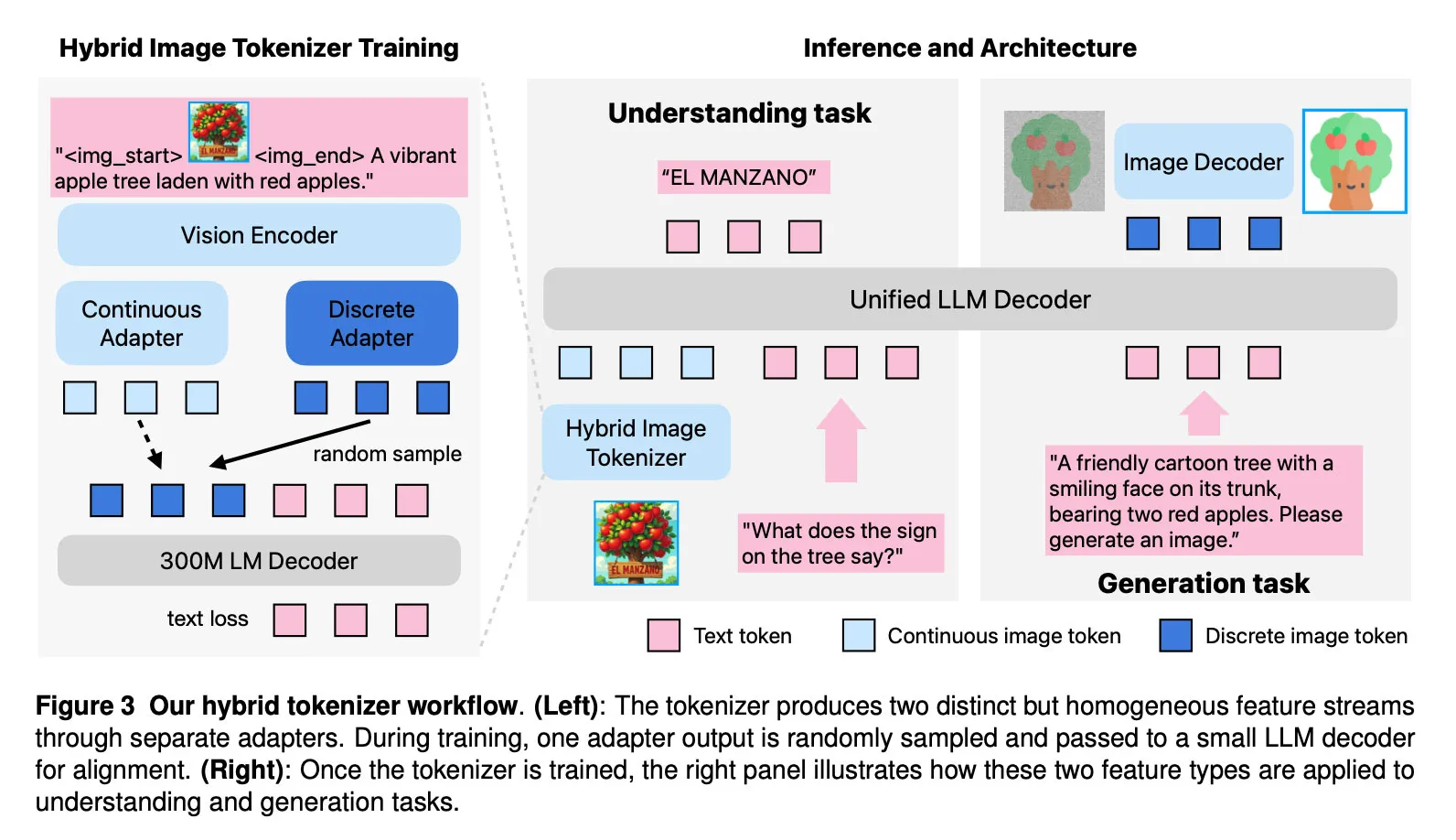
Apple spiega che Manzano integra tre componenti principali:
- Hybrid vision tokenizer: produce rappresentazioni visive sia continue sia discrete.
- LLM decoder: riceve token testuali e/o embedding continui e prevede in modo autoregressivo i token successivi di testo o immagine da un vocabolario congiunto.
- Image decoder: trasforma i token predetti in pixel tramite il processo di diffusione.
Prestazioni del modello
Secondo i ricercatori:
“Manzano gestisce prompt controintuitivi o che sfidano le leggi della fisica (ad esempio: “L’uccello vola sotto l’elefante”) con prestazioni paragonabili a GPT-4o e Nano Banana.”

Nei test, i modelli Manzano 3B e 30B hanno mostrato performance superiori o competitive rispetto ad altri modelli multimodali unificati all’avanguardia.
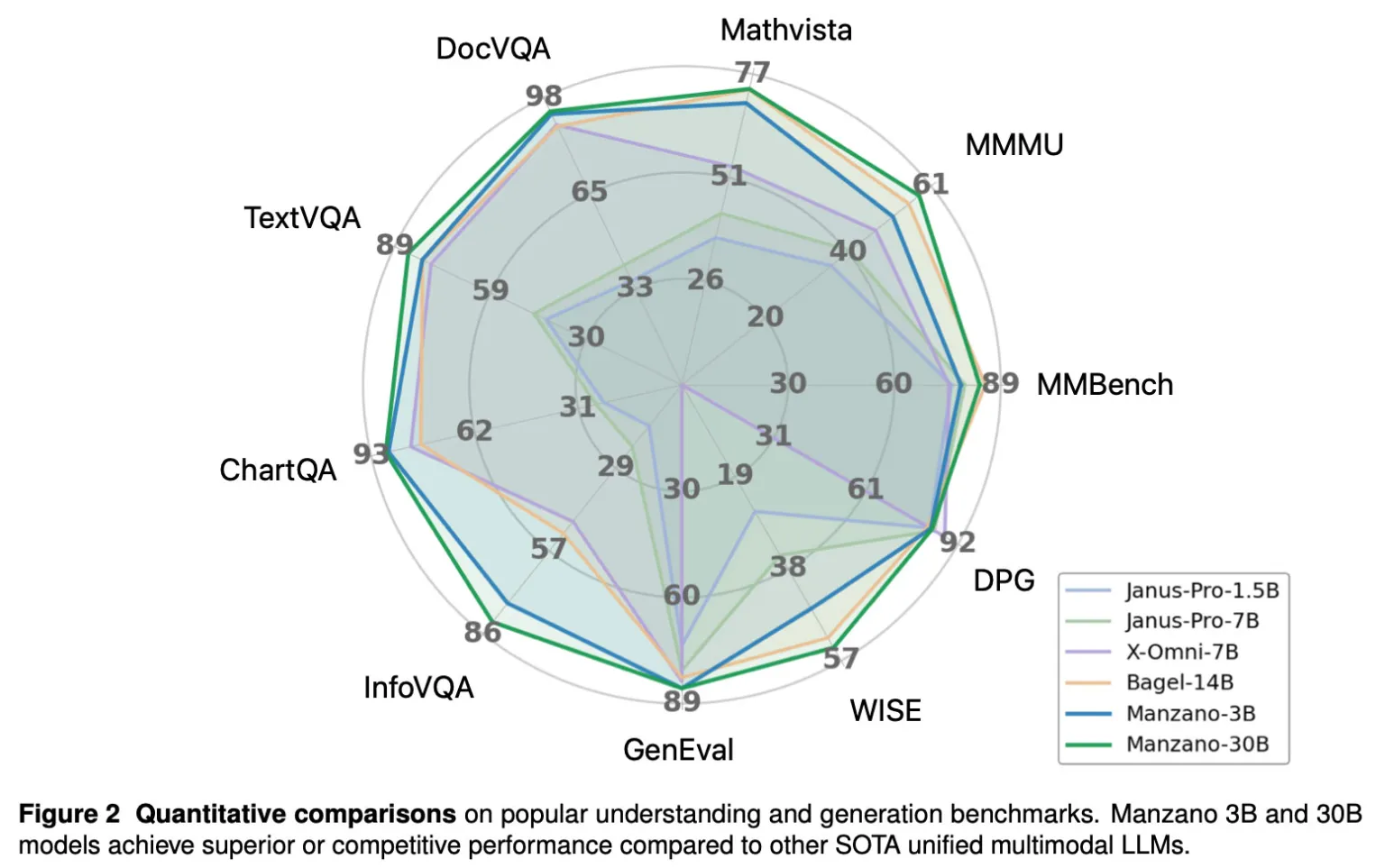
Apple ha sperimentato il modello su diverse dimensioni, da 300 milioni a 30 miliardi di parametri, per valutare come le prestazioni multimodali migliorino con la scala.

Un confronto con modelli come GPT-4o e Nano Banana conferma la competitività di Manzano in più metriche chiave.

Applicazioni e prospettive
Manzano è stato testato anche su compiti di generazione e comprensione visiva complessi. Lo studio indica che il modello potrebbe avere un ruolo rilevante in futuri strumenti Apple come Image Playground, anche se non è ancora disponibile sui dispositivi della società.

Il paper completo include dettagli su addestramento del tokenizer ibrido, design del decoder di diffusione, esperimenti di scaling e valutazioni umane. Apple rimanda inoltre ad altri modelli recenti, come UniGen, che confermano la direzione della ricerca interna in ambito generazione immagini.























































































Leggi o Aggiungi Commenti