
Apple ha rilasciato Pico-Banana-400K, un nuovo dataset di ricerca da 400.000 immagini progettato per addestrare e testare modelli di intelligenza artificiale dedicati all’editing di immagini guidato dal testo.Il progetto, pubblicato insieme a uno studio tecnico suXiv, è il risultato di un approccio curioso, perché la società ha usato i modelli Gemini-2.5 di Google per costruirlo.
Il dataset è distribuito con licenza di ricerca non commerciale, il che significa che può essere liberamente utilizzato da università, laboratori e ricercatori, ma non per fini commerciali.
Come è nato Pico-Banana-400K
Apple ha selezionato migliaia di fotografie reali dal dataset pubblico OpenImages, garantendo varietà tra immagini di persone, oggetti e scene testuali. Su questa base, i ricercatori hanno definito 35 tipologie di modifiche possibili, suddivise in otto categorie, che un utente potrebbe chiedere a un modello di image editing.
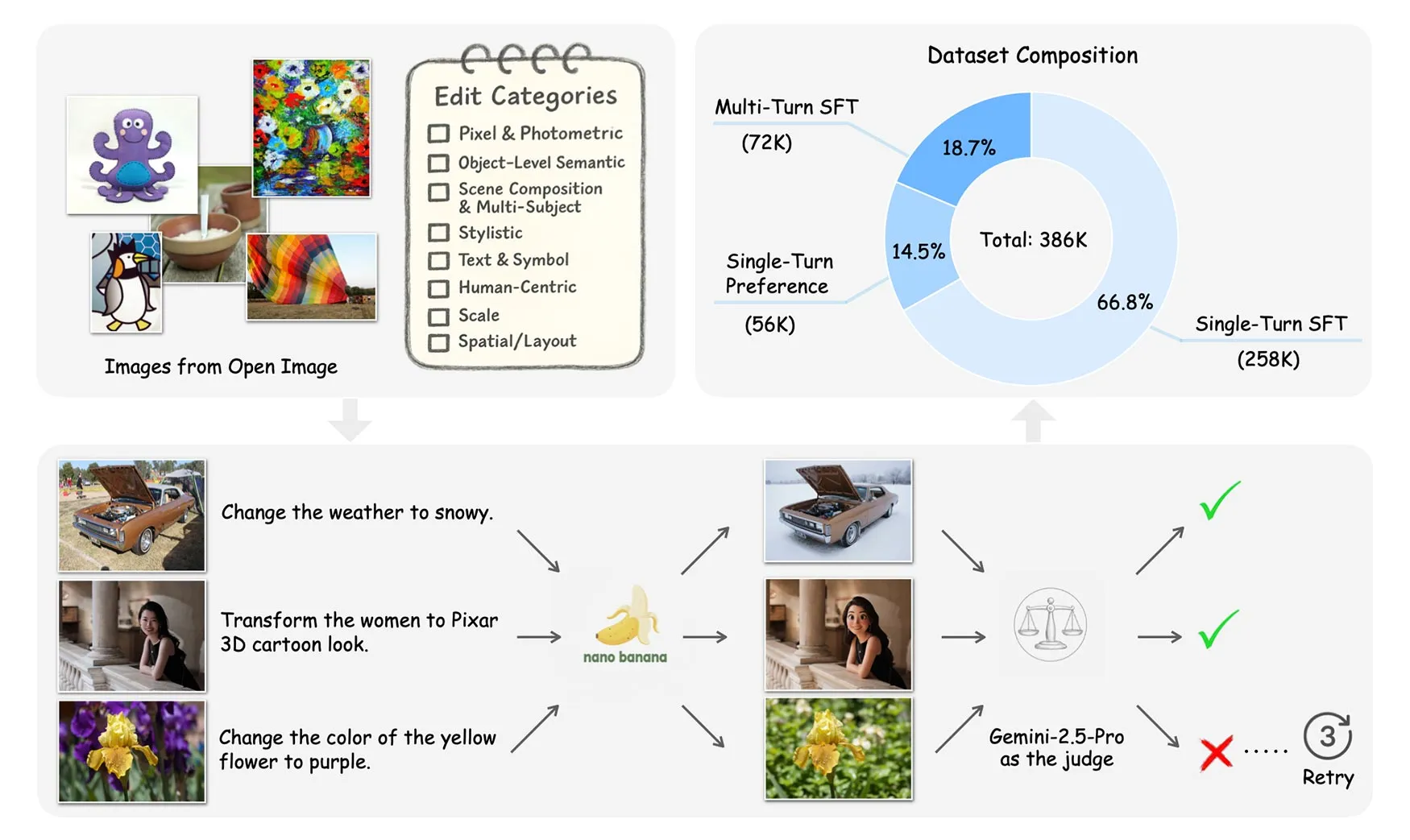
Tra queste troviamo cambi di luce o colore (“aggiungi grana analogica” o “applica filtro vintage”), trasformazioni umane (“crea versione Funko-Pop del soggetto”), modifiche ambientali (“rendi la scena piovosa o soleggiata”) e persino manipolazioni spaziali come “sposta un oggetto” o “zoom in”.
Ogni immagine veniva elaborata dal modello Nano-Banana (una versione del Gemini-2.5-Flash-Image), mentre un secondo modello, Gemini-2.5-Pro, valutava i risultati approvando o scartando le generazioni in base alla fedeltà all’istruzione e alla qualità visiva.

Il risultato è un dataset che include editing singoli, sequenze iterative di editing multiplo e persino coppie di preferenza, ossia esempi che mostrano al modello cosa rappresenta un risultato corretto e cosa invece no.

Gli stessi ricercatori di Apple sottolineano come, nonostante i progressi di modelli recenti, la ricerca aperta sia ancora limitata dalla mancanza di dataset di alta qualità e completamente condivisibili. Pico-Banana-400K nasce proprio per colmare questa lacuna, offrendo una base ampia e coerente per il training e il benchmarking dei futuri modelli di AI dedicati all’image editing basato su testo.
Il dataset e la documentazione ufficiale sono già disponibili su GitHub, mentre lo studio completo è consultabile su arXiv.















































































































Leggi o Aggiungi Commenti