
In questi anni, Apple si è gradualmente avvicinata all’esecuzione locale dell’intelligenza artificiale generativa, sfruttando al massimo la propria architettura hardware. Coerentemente con questo percorso, l’ultimo post pubblicato sul blog Machine Learning Research svela quanto è più veloce il nuovo chip M5 rispetto all’M4 quando deve gestire un LLM in locale.

Per capire il quadro serve un breve richiamo a MLX, il framework open-source che Apple definisce “un array framework efficiente e flessibile per il machine learning su Apple silicon”. Nella pratica rappresenta l’interfaccia più immediata per chi vuole costruire o eseguire modelli nativamente su macOS, con un’API che ricalca NumPy e con un’integrazione diretta con CPU e GPU grazie alla memoria unificata.
Nel post troviamo anche una descrizione completa, che Apple riporta così:
“MLX è un framework open source per array che è efficiente, flessibile e ottimizzato per Apple silicon. MLX facilita la generazione di testo o il fine tuning di modelli linguistici di grandi dimensioni su dispositivi Apple silicon.”
Tra i pacchetti più utilizzati c’è MLX LM, pensato per generare testo e affinare modelli su Mac con Apple silicon. Possiamo scaricare modelli da Hugging Face e avviarli in locale, sfruttando anche la quantizzazione, una tecnica di compressione che riduce memoria e compute necessari durante l’inferenza.
La quantizzazione diventa particolarmente utile nel contesto dei MacBook Pro con memoria limitata: permette di far girare LLM di dimensioni molto più elevate senza saturare le risorse, riducendo anche la latenza nella generazione del testo. Da qui nasce il confronto M4–M5: Apple vuole mostrare quanto il nuovo chip riesca a valorizzare questo tipo di workload.
Nel confronto diretto, Apple spiega:
“Valutiamo Qwen 1.7B e 8B in precisione BF16, e i modelli quantizzati a 4 bit Qwen 8B e Qwen 14B. Oltre a questi, testiamo due Mixture of Experts: Qwen 30B (3B attivi, 4-bit) e GPT OSS 20B (MXFP4). I risultati includono il tempo al primo token e la velocità di generazione.”
La misurazione del primo token è particolarmente interessante perché rivela quanto il chip sia efficace nel carico puramente computazionale: infatti questa fase è compute-bound. La generazione dei token successivi è invece memory-bound e mette in evidenza la banda di memoria disponibile.
E qui entra in gioco una delle principali differenze dell’M5. La nuova GPU con Neural Accelerators dedicati alle operazioni di matrice, fondamentali per il machine learning.
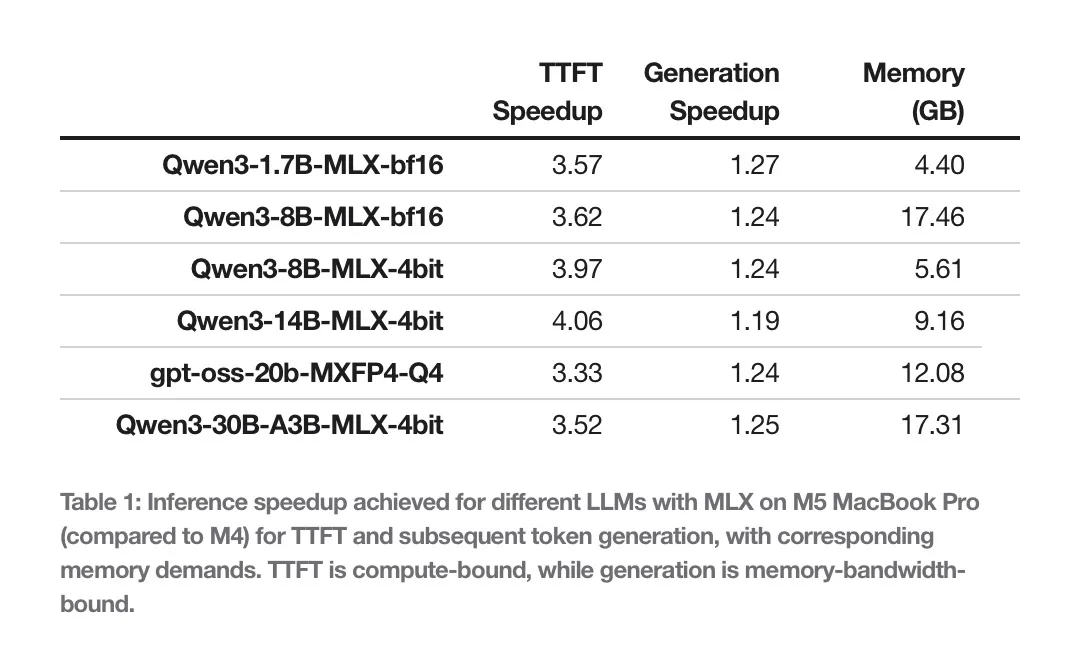
Dalle tabelle pubblicate nel post emerge un quadro chiaro. Nel primo token, il vantaggio dell’M5 si vede già in modo netto, ma è nella generazione continuata dei successivi 128 token che la forbice diventa più evidente.
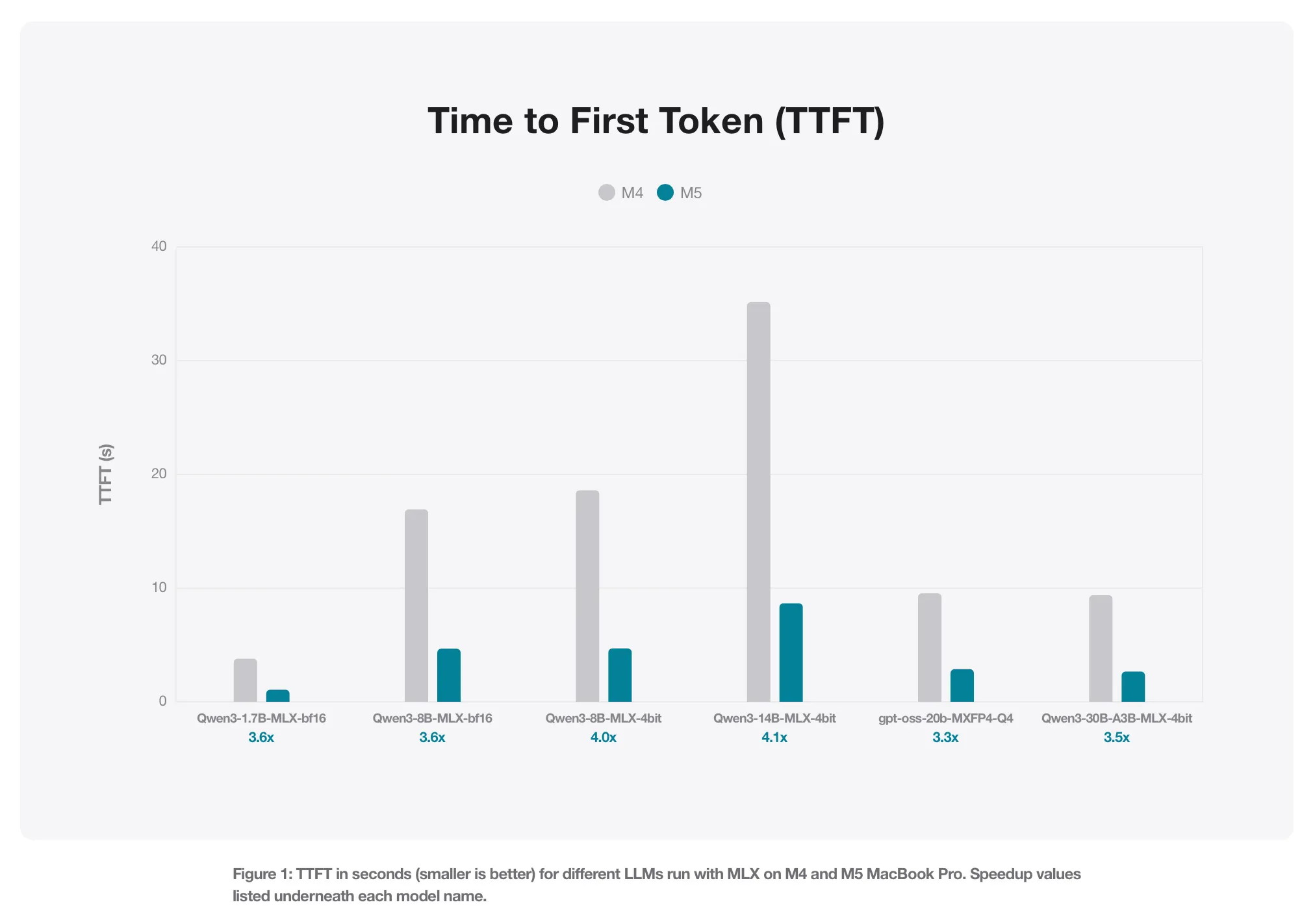
Apple riassume così:
“L’M5 fornisce un boost prestazionale tra il 19 e il 27% rispetto all’M4, grazie alla maggiore banda di memoria: 120 GB/s sull’M4, 153 GB/s sull’M5, cioè il 28% in più.”
Interessante anche il commento sulla memoria dei MacBook Pro con 24 GB. Secondo Apple possono ospitare tranquillamente modelli da 8B in BF16 oppure un 30B quantizzato a 4 bit, restando sotto i 18 GB di footprint.
Nello stesso articolo troviamo anche un riferimento ai workload di generazione di immagini, dove l’M5 sembra ottenere un incremento ancora più marcato: oltre 3,8 volte più veloce dell’M4. Un dato che conferma come la nuova architettura sia stata pensata in modo specifico per dare più respiro alle operazioni AI-intensive.





Commenta l'articolo per primo
Accedi per lasciare un commento: