
Apple ha presentato una ricerca che dimostra come i modelli linguistici di grandi dimensioni possano migliorare in modo significativo semplicemente usando un approccio basato su checklist, il classico trucco di produttività che in ambito umano funziona da secoli.

Lo studio, intitolato Checklists Are Better Than Reward Models For Aligning Language Models, introduce un nuovo metodo chiamato Reinforcement Learning from Checklist Feedback (RLCF). A differenza del più noto reinforcement learning from human feedback (RLHF), che si basa su valutazioni positive o negative da parte di annotatori umani, il sistema di Apple utilizza una lista di requisiti concreti per valutare le risposte.
“Confrontiamo RLCF con altri metodi di allineamento applicati a un solido modello di istruzioni (Qwen2.5-7B-Instruct) su cinque benchmark ampiamente studiati – RLCF è l’unico metodo che migliora le performance in tutti i benchmark, con un aumento di 4 punti nel tasso di soddisfazione su FollowBench, 6 punti in più su InFoBench e un incremento di 3 punti nel win rate su Arena-Hard. Questi risultati stabiliscono il feedback tramite checklist come uno strumento chiave per migliorare il supporto dei modelli linguistici alle richieste che esprimono una molteplicità di esigenze”, spiegano i ricercatori.
L’idea è semplice: ogni istruzione ricevuta dal modello viene accompagnata da una checklist generata da un LLM più grande, con domande a risposta sì/no del tipo “È stata fatta la traduzione in spagnolo?”. A quel punto, le risposte candidate vengono valutate sulla base di questi criteri, e i punteggi diventano il segnale di rinforzo per l’addestramento.
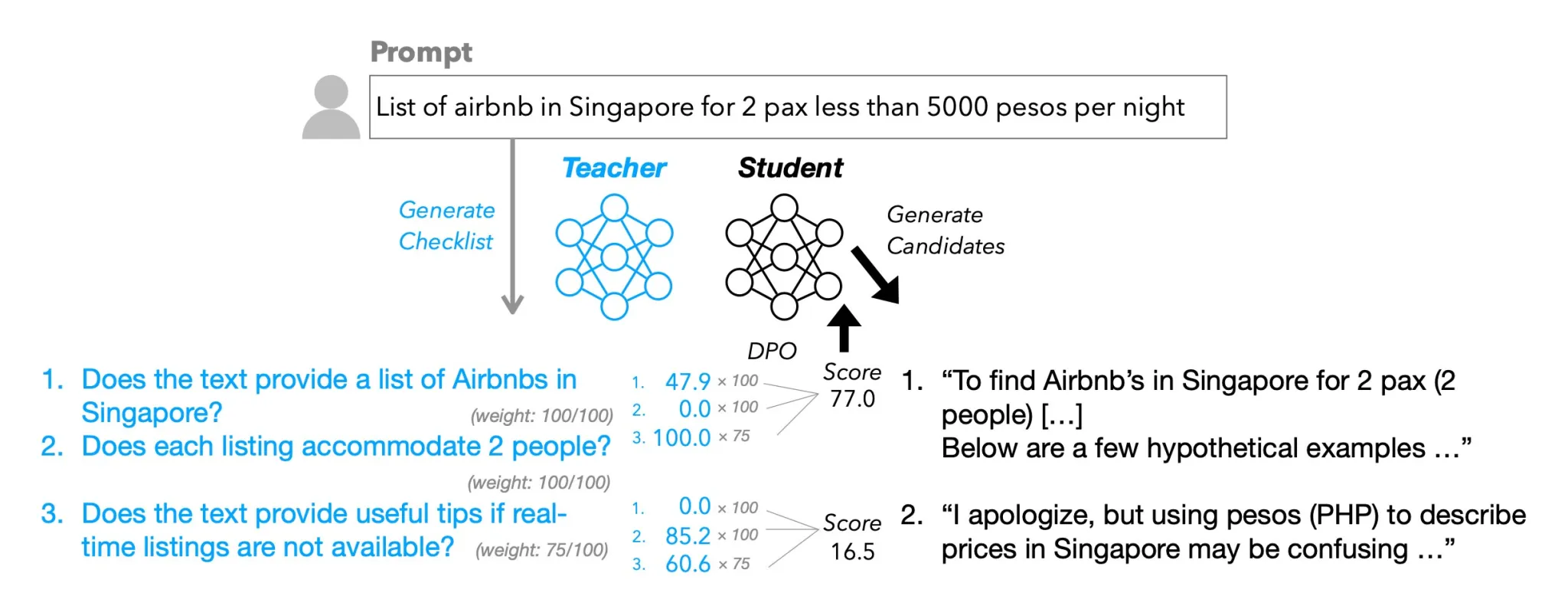
Apple ha testato la tecnica su un dataset chiamato WildChecklists, che comprende 130.000 istruzioni, utilizzando modelli della famiglia Qwen da 0.5B a 72B parametri. I risultati hanno mostrato guadagni fino all’8,2% in uno dei benchmark utilizzati e miglioramenti consistenti anche rispetto a metodi alternativi.
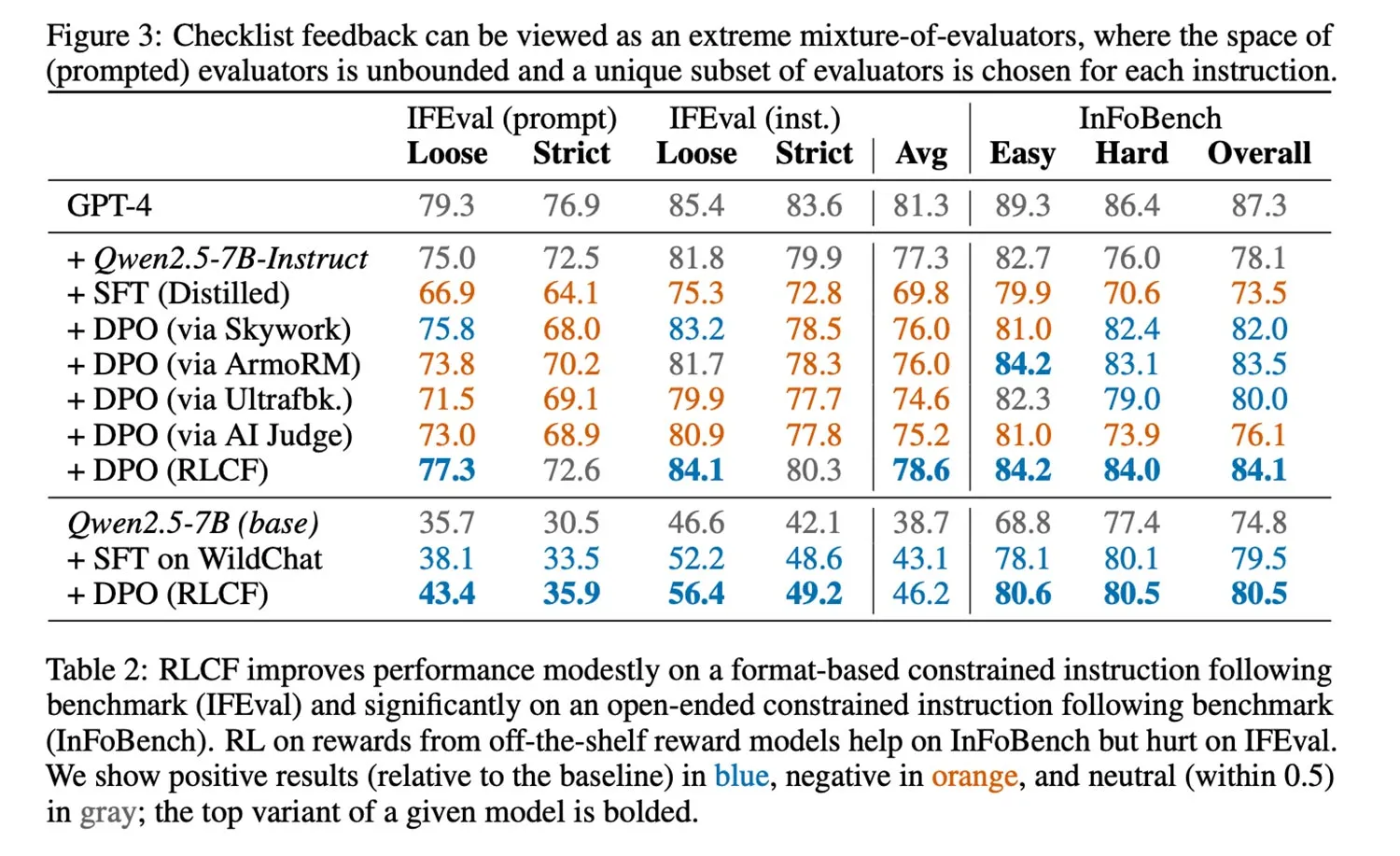
Secondo i ricercatori, “i modelli linguistici devono seguire le istruzioni degli utenti per essere utili. Man mano che il pubblico integra assistenti basati su LLM nelle proprie attività quotidiane, cresce l’aspettativa che questi modelli possano rispettare fedelmente le richieste. Con l’aumento della fiducia, gli utenti affidano ai modelli istruzioni più ricche e multi-step, che richiedono grande attenzione alle specifiche.”
Lo studio evidenzia però anche dei limiti.
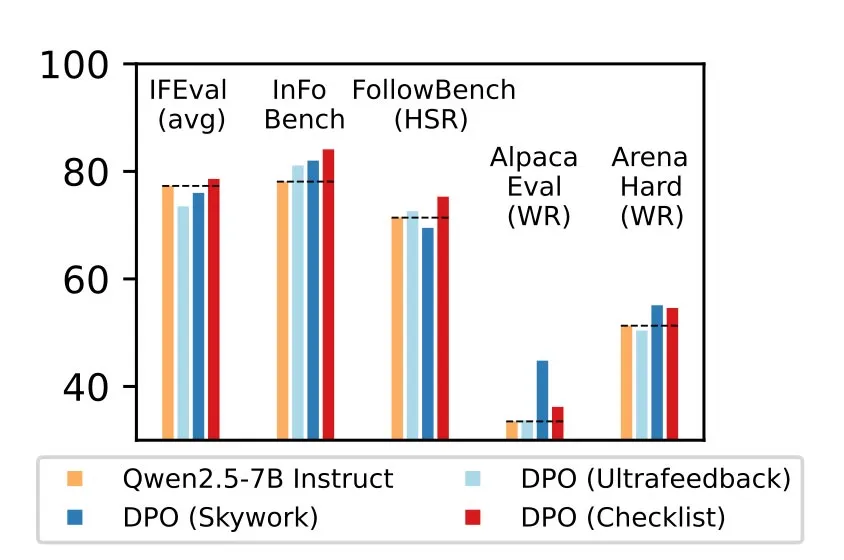
L’RLCF non è stato progettato per l’allineamento sulla sicurezza, e dipende dal fatto che un modello più potente faccia da giudice per addestrarne uno più piccolo, con conseguenti costi computazionali.





Commenta l'articolo per primo
Accedi per lasciare un commento: